Notes on CVPR 2019
This is a note of thoughts and summaries of what is seen and heard at CVPR 2019. It will mainly be about papers related to NLG and Language+Vision.
Though CVPR focuses on the Computer Vision part of AI. This year, there are more papers about combination of Language and Vision, showing the increased importance of language in deep understanding of an image. This post takes a quick look at those papers related to language, and thinks about some interesting ideas.
Overview of selected topics:
Workshops
- Conceptual Captions Challenge This is a workshop which talks about a new image caption generation task of producing a natural-language utterance.
- Visual Question Answering and Dialog
Papers
- Language
- Cycle Consistency
- Image Synthesis
- Adversarial Learning
- VQA
- Semantic Navigation
- Dataset
- From Recognition to Cognition: Visual Commonsense Reasoning
- Fashion IQ Dataset [pdf] [project]
Misc
- Video Action Transformer Network Transformer Architecture being used for Video classification task.
Adversarial Learning for NLP
SeqGAN (Yu et al, 2017) is the first paper which applies GAN to text generation. Since SeqGAN, there are many other papers following the idea. However, there are also many critisism about the usefulness and reproducibility of those papers. (Stanislau Semeniuta, et al. 2018; Caccia et al., 2018; Tevet et al., 2018) Also, most of these text GAN papers require warm-start, meaning that they need to use MLE to pretrain the generator. However, during the adversarial training stage, the learning rate is set to be very small, and it becomes difficult to analyze how much the adversarial training helps.
In CVPR, there are some papers using GAN’s idea to generate text. However, none of them only relies on adversarial loss for training. I have talked to serveral authors about only using adversarial loss for training. It seems that they all have encountered unstable training and mode collapse when doing that. So it may conclude that unlike what is advertised in SeqGAN and its following papers, it is very hard to improve the language generation quality by training with adversarial loss alone. I also personally doubt that replacing vanilla GAN with Wasserstein GAN and its variants would work because of the discreness of language. I hope in the future someone could give a more mathematical perspective of why GAN fails in language generation.
Back to the point, however, the three papers I have found in CVPR use different ways of applying adversarial learning to improving language generation.
Adversarial Inference
The first paper Adversarial Inference for Multi-Sentence Video Descriptions has a very simple idea about leveraging discriminator. To avoid the problem brought by adversarial training, this paper choose only to do adversarial inference. Here, we only look at the language discriminator, and it calculates a score between 0 and 1 using the last hidden state:
\[\begin{equation} D_L(s_i) = \sigma(W_L h^i + b_L) \end{equation}\]The score from the language discriminator can be used to detect how real/fake the generated sentence is compared to the real sentences. Notice that in the paper “Defending Against Neural Fake News.” (Zellers et al., 2019), the authors have proposed a similiar idea by training a seperate discriminator to detect fake news generated by the neural model. But here, the idea can be extended to use the trained discriminator to rank a list of generated sentences sampled from the generator.
Discriminator is not used to help the generator any more. Generator is still trained with MLE. Discriminator is trained seperately to differentiate between real data and generated data. Most of the time, discriminator would be trained successfully to be capable of learning the subtle differences between real and fake. The paper has shown results that such subtle differences could be information like logic or common sense, but it might need more detailed analysis of what is learned for the discriminator to lead more clear conclusion. Also, the paper did not test Nucleus sampling (Holtzman et al, 2019) compared with beam search, which might reduce some of problems due to sampling.
Anyway, here are some results. You can check the paper for details of notations:
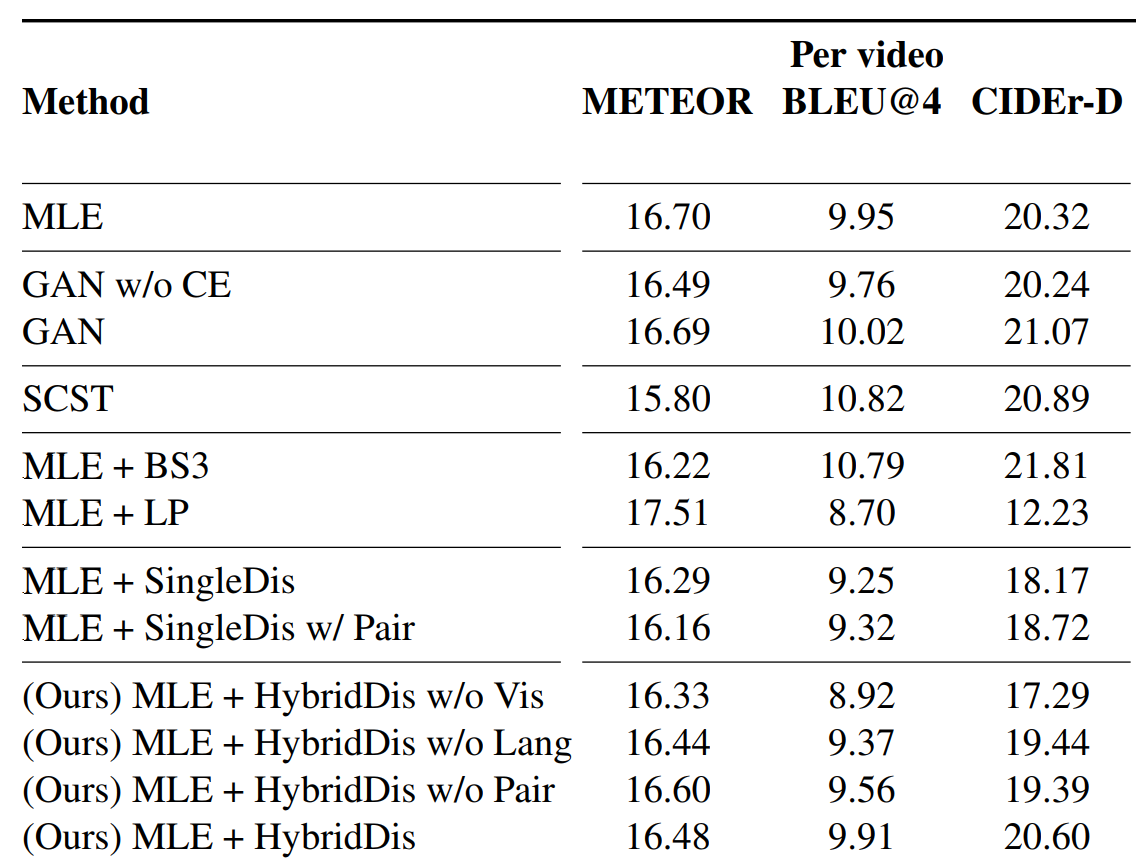
From the results of automatic evaluation metrics - METEOR, BLEU-4, and CIDEr-D, it is hard to decide which one is better. This is just due to the fact to evaluate the quality of generated samples, it needs a more powerful model that itself. In this case, it can only be human. Below is the results from human evaluation:
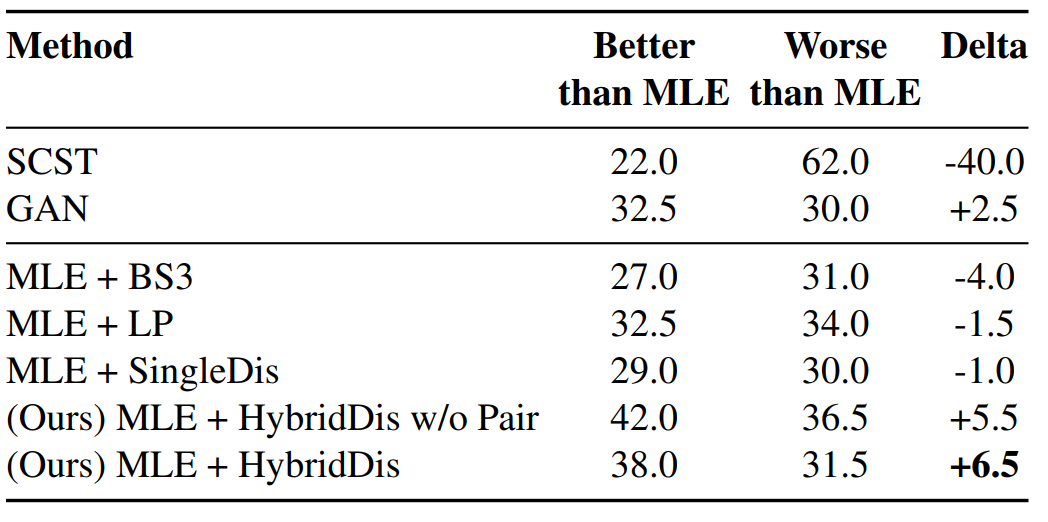
Now the scores become much more clear for comparison of which model is better. From the table, we can observe that the authors proposed model achieves the highest human evaluation score, while automatic evalution metrics cannot truly correlate with the human perceived quality.
Some generated outputs: Red/bold indicates content errors, blue/italic indicates repetitive patterns.
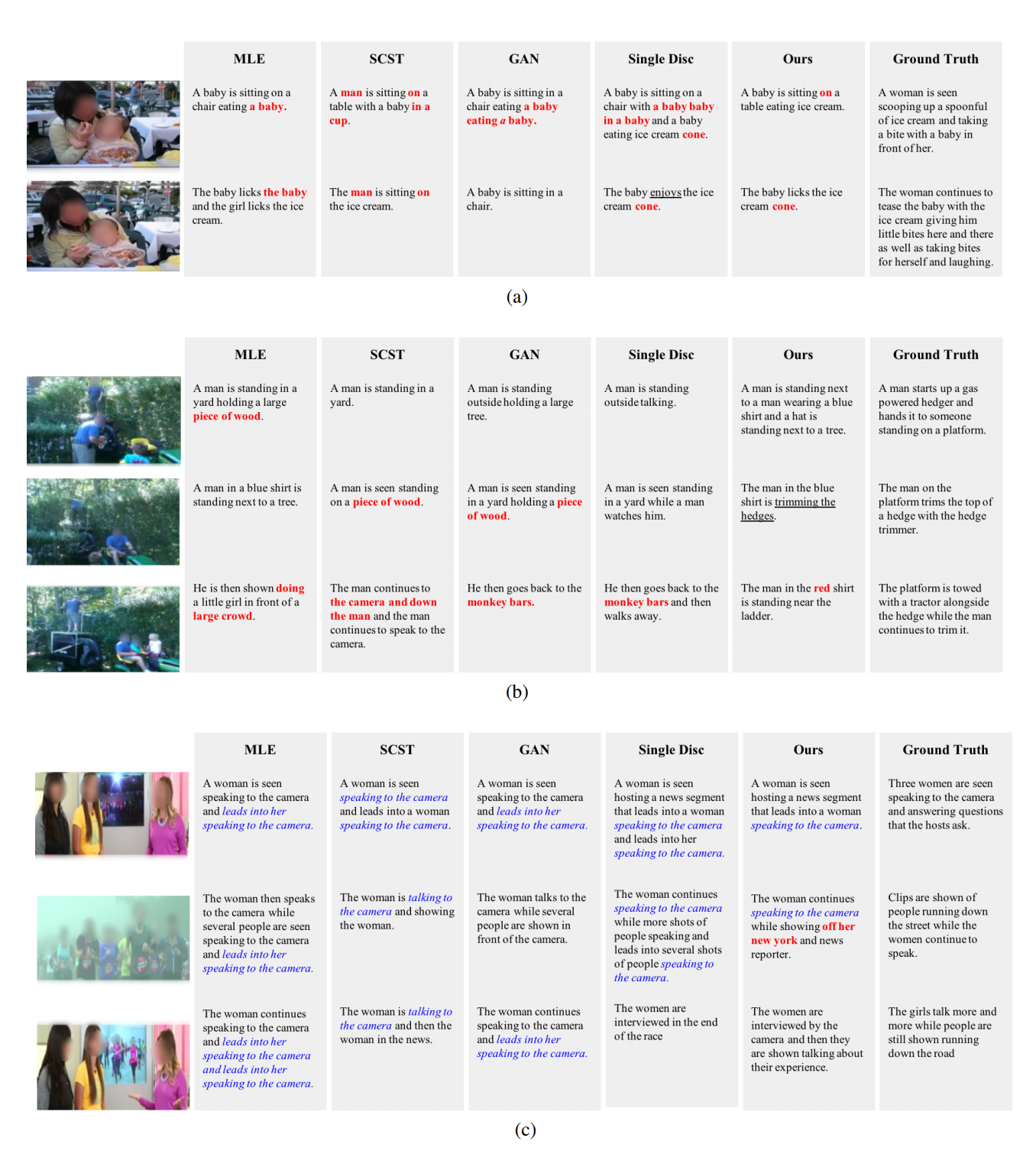
Overall, the paper Adversarial Inference for Multi-Sentence Video Descriptions provides a way of using adversariall learned discriminator for inference. It might be possible that other NLG tasks can also benefit from using method, which can be a good direction to explore.
Adversarial Filtering
There are also older papers mentioning the application of training an adversarial discriminator as a ranking score to improve the quality of generation. SWAG: A Large-Scale Adversarial Dataset for Grounded Commonsense Inference (Zellers et al, 2018) is the very first paper using such idea.
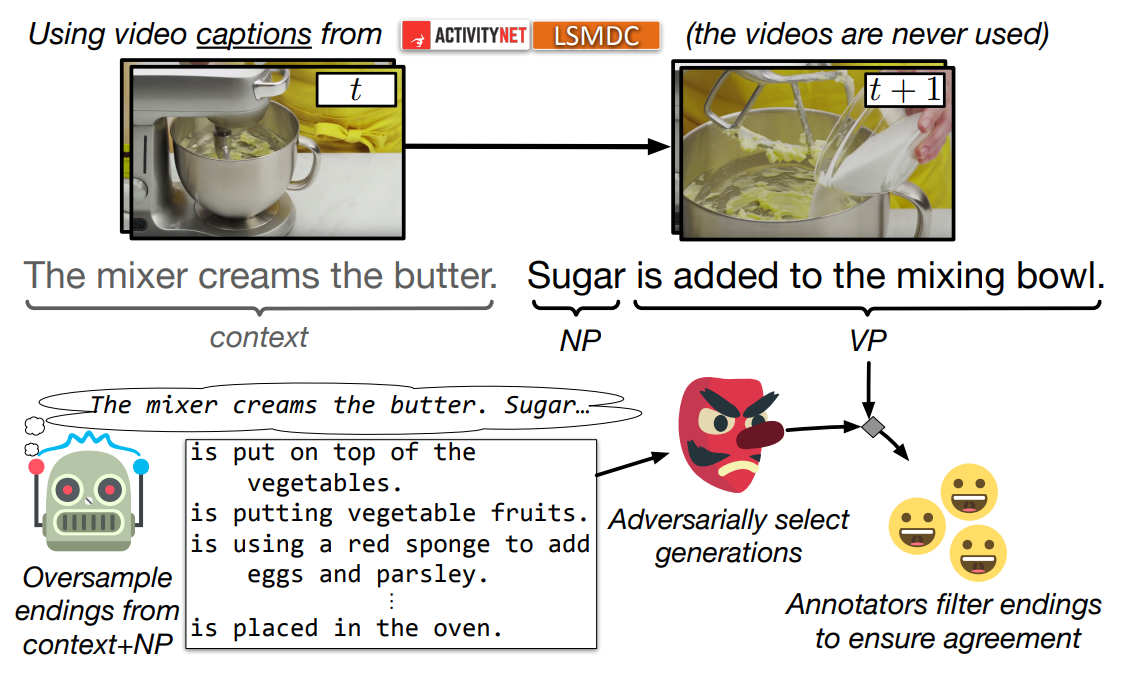
This figure shows a basic SWAG pipeline of creating the dataset. A neural generator is trained to generate endings for the video captions. Another discriminator is also trained to adversarially recognize real and fake endings. Then those generated endings with high discriminator score are picked, and later humans will further filter them. In this way,the authors can easily create thousands of generations as ground truth with very little human annotations.
There is also a follow-up work HellaSwag: Can a Machine Really Finish Your Sentence? (Zellers et al, 2019). It tests different cases when using LSTM or GPT as the generator and BERT as the discriminator. And by combining the newest classification and generative models, it has created the most chanllenging commonsense dataset so far.
Combining Adversarial Loss
For “Unsupervised Image Captioning” and “MSCap: Multi-Style Image Captioning With Unpaired Stylized Text”, these two papers use another approach to leverage adversarial learning. Since training with adversarial loss alone is not possible, is it possible to combine different sources of loss together?
Here, we only take a brief look at the loss constuction and leave the remaining details for readers. In “Unsupervised Image Captioning”, the authors use an idea similiar to CycleGAN (Zhu et al, 2017). The task is formulated as to do image-to-text and text-to-image generation. Then two discriminators need to help to differentiate real/fake in both image and text domains. As we mentioned before, adversial loss alone is not enough. Therefore, the authors have included some other losses such as “concept loss” for the overlap of image objects and generated entities:
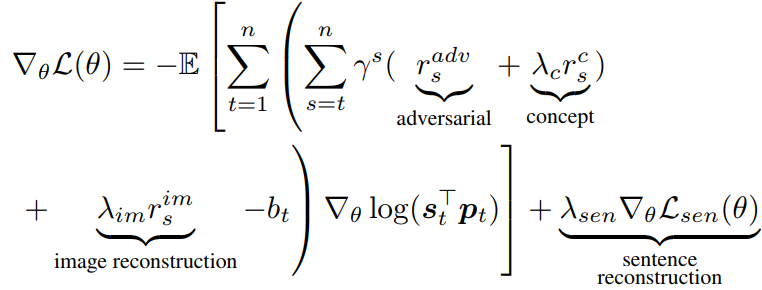
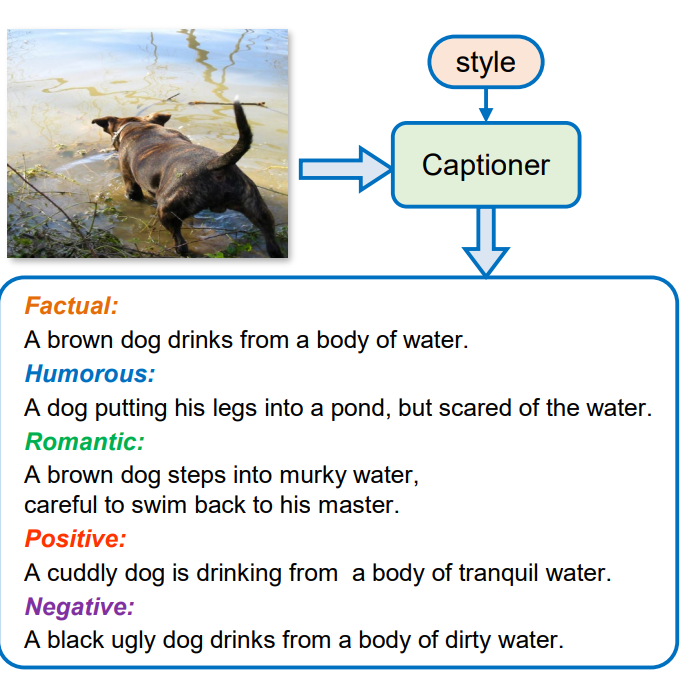
In the other paper “MSCap: Multi-Style Image Captioning With Unpaired Stylized Text”, it want to change the style of the caption conditioned on the style input:
The basic idea is from conditional GAN (Mirza et al, 2014). Conditional GAN jointly optimize the classification loss and adversarial loss. In this paper, to stablize the training, the authors have combined MLE loss. The resulting loss function becomes:
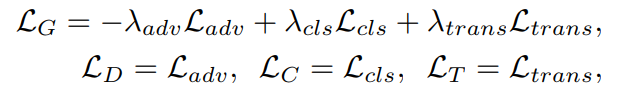
To summarize, adversarial learning has great potentials in NLG due to its properties. However, vanilla adversarial training method cannot be directly used for text generation. Right now, it seems there are two methods which are promising: adversarial inference and MLE+GAN. But before widely use them as well-established methods, we want to first figure out some questions. (1) Can adversarial inference help to improve all other text generation tasks? (2) Does MLE+GAN really improve the generation quality or it hurts the quality but enables some other features (style-transfer, latent variables)? (3) Pretrained language model helps sub-stream generation tasks, but training with adversarial loss combined with MLE might cause catastrophic forgetting. How to analyze it?
Self-supervised Imitation Learning
In language generation tasks, Maximum Likelihood Estimation (MLE) is often used as the standard objective for training. In the context of reinforcement learning, MLE is called “Imitation Learning”. When doing Self-supervised Imitation Learning, it means that we want the model to learn from its past good decisions. It can be done by first sampling some sequences and using a rank or score metric to pick the best N generated sequences. Then we apply MLE again to train on those new generated sequences. (There should be a replay buffer to store them.)
For the paper Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation (Want et al, 2019), the authors used such approach to train an agent that can understand instructions to navigate the room. The results show that SIL is effective and robust in unseen environments.
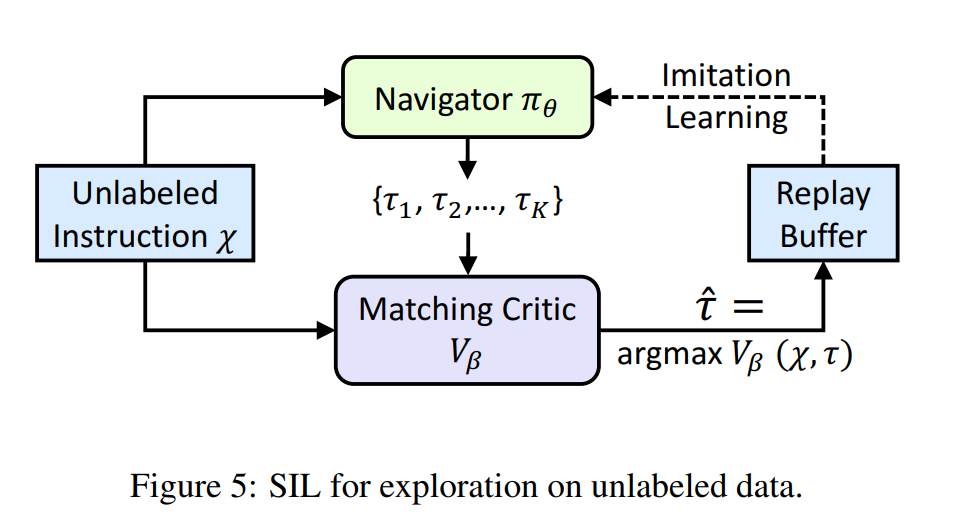
Fig. The pipeline for how to train with Self-supervised Imitation Learning.
Cycle Consistency
Cycle consistency is often used as a loss function to improve the stability and consistency of the generated samples. The idea is very similar and originates from a machine translation paper called Dual Learning (He et al, 2016). If there can be found such cycle consistency, the quality of generation can be greatly improved.
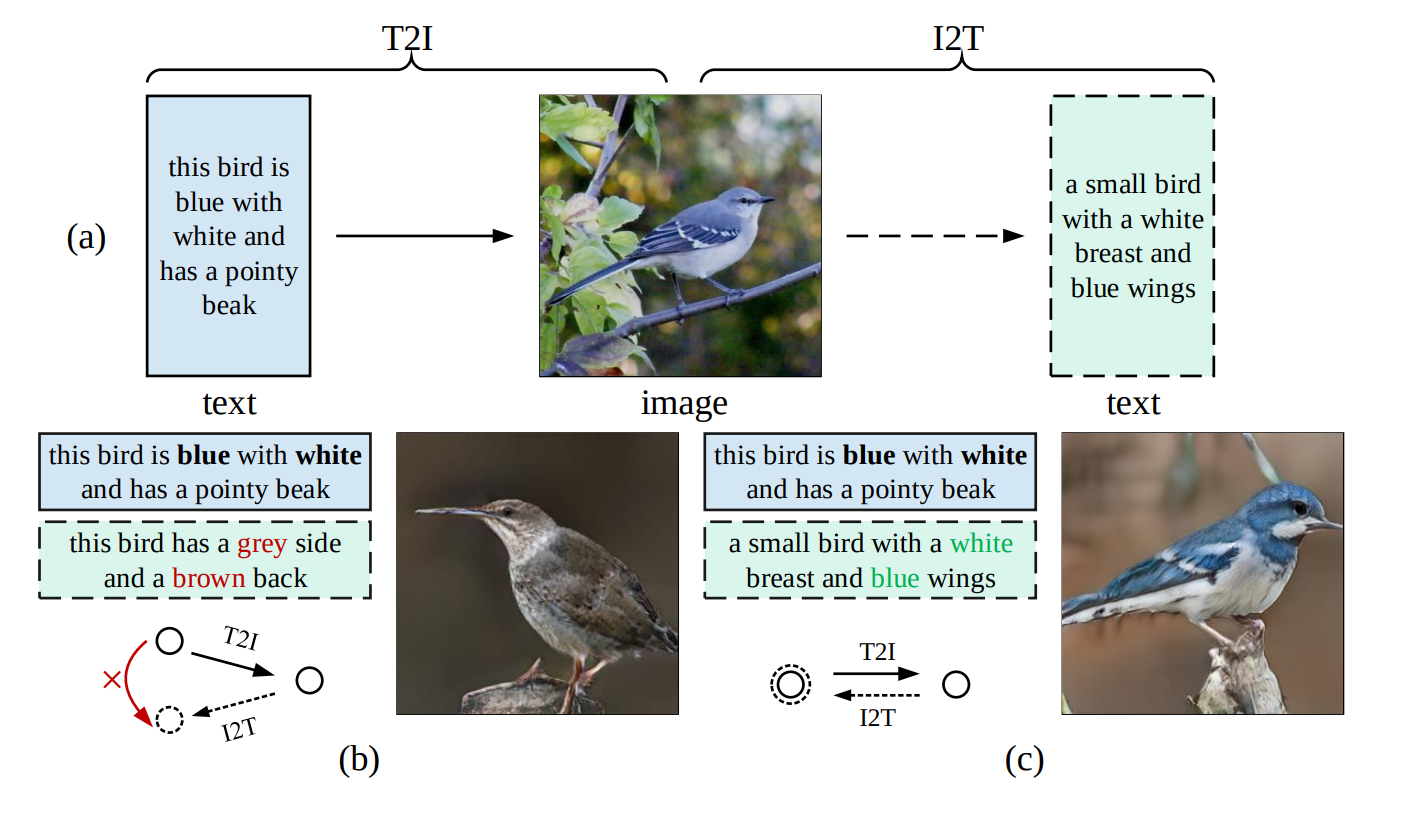
The figure is from MirrorGAN (Qiao et al, 2019). It leverges consistency from text-to-image and image-to-text. The result shows that the generated image is more language grounded, and the generated sentence description is also more vision grounded.
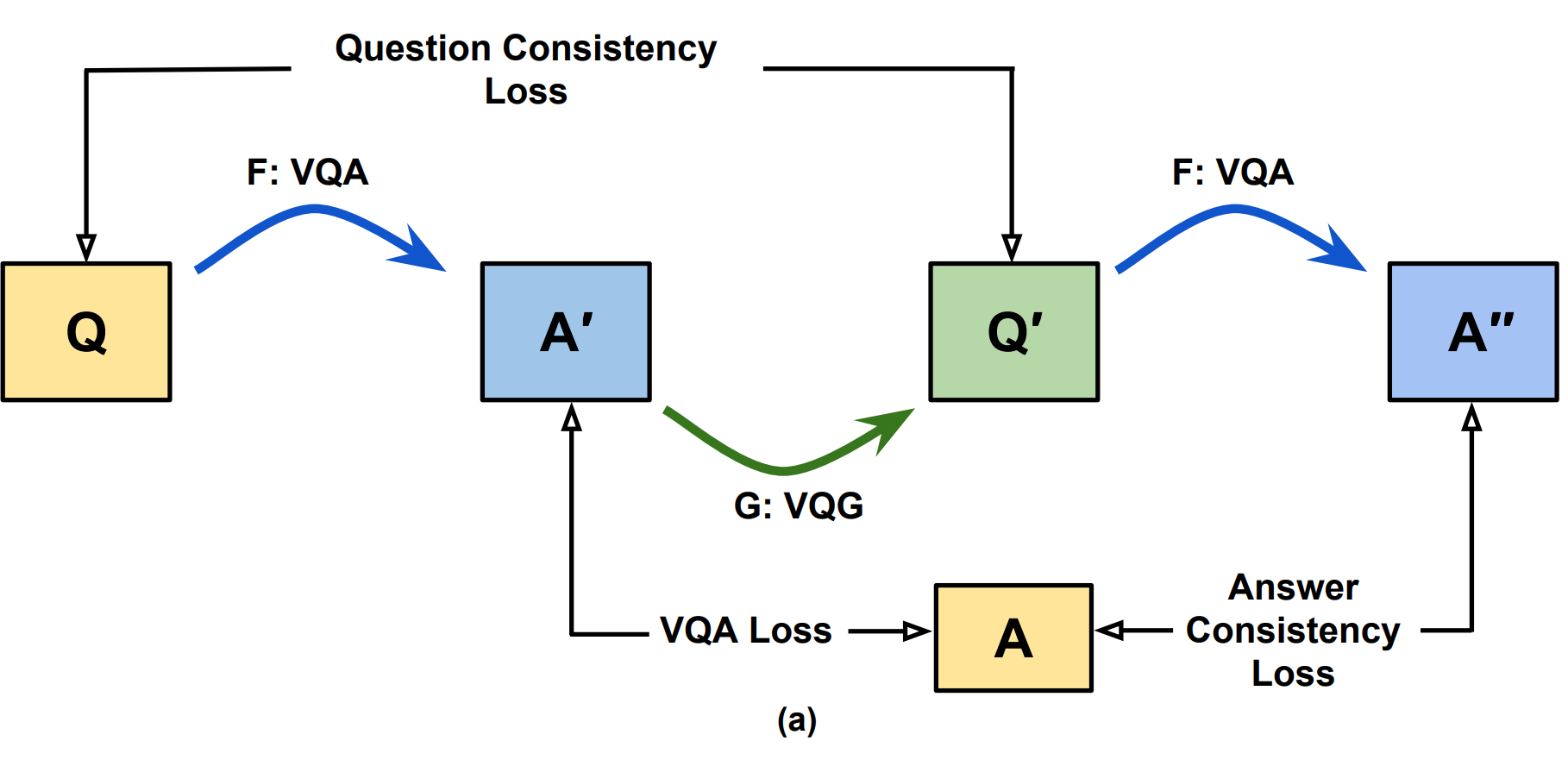
In another paper Cycle-Consistency for Robust Visual Question Answering (Shah et al, 2019), the authors leverage the consistency from question-to-answer and answer-to-question, and the results are convincing.
Text-to-Image Synthesis
One interesting paper is Semantics Disentangling for Text-to-Image Generation (Yin et al, 2019). In this paper, it has achieved to generate photo-realistic images from text description.
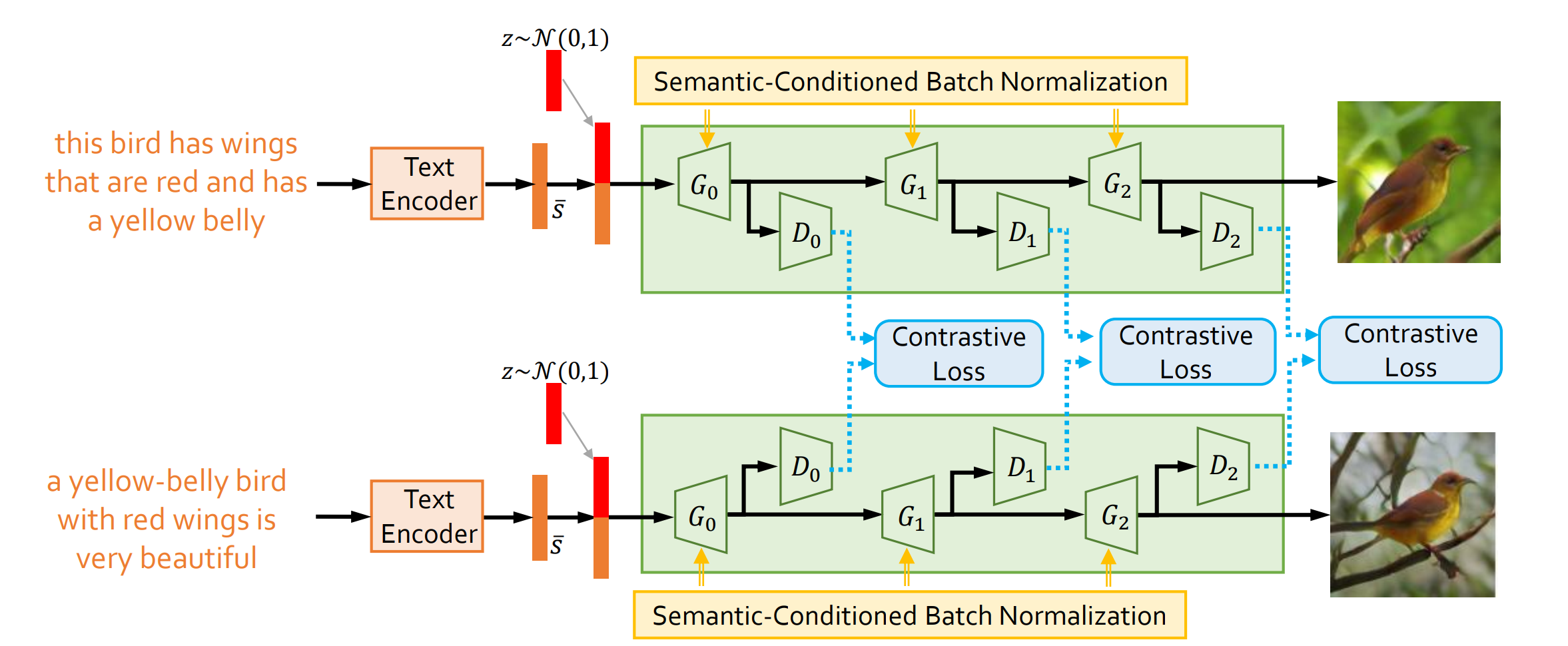
The above figure is a pipeline illustration for this paper. The text description is first encoded by LSTM into a sentence embedding \(\bar{s}\). \(z \sim \mathcal{N}(0, 1)\) is the random noise input for GAN. The structure contains multiple stages of generation. The image resolution increases after each stage, and for images generated in each stage, there is corresponding discriminator. One contribution of this paper is that it proposes to use contrastive loss to learn the embedding for sentences. The formula is written as below:
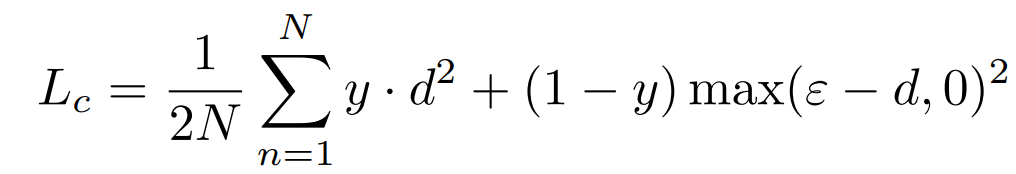
In which, \(y\) marks whether the input descriptions are from the same image (or from the same bird). 1 for yes and 0 for no. \(d\) represents the distance between two visual feature vectors. Therefore, the discriminator needs to output both a visual feature vector and a real/fake score.
[1] Lantao Yu, et al. “SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient.” AAAI 2017
[2] Stanislau Semeniuta, et al. “On Accurate Evaluation of GANs for Language Generation.” arxiv:1806.04936
[3] Massimo Caccia, et al. “Language GANs Falling Short.” arxiv:1811.02549
[4] Guy Tevet, et al. “Evaluating Text GANs as Language Models.” arxiv:1810.12686
[5] Rowan Zellers, et al. “Defending Against Neural Fake News.” arxiv:1905.12616
[6] Ari Holtzman, et al. “The Curious Case of Neural Text Degeneration.” arxiv:1904.09751
[7] Jun-Yan Zhu, et al. “Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks.” ICCV 2017
[8] Mehdi Mirza, et al. “Conditional Generative Adversarial Nets” arXiv:1411.1784
[9] Rowan Zellers, et al. “SWAG: A Large-Scale Adversarial Dataset for Grounded Commonsense Inference” EMNLP 2018
[10] Rowan Zellers, et al. “HellaSwag: Can a Machine Really Finish Your Sentence?” ACL 2019
[11] Xin Wang, et al. “Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation” CVPR 2019
[12] Di He, et al. “Dual Learning for Machine Translation” NIPS 2016