Importance-Aware Learning for Neural Headline Editing
Many social media news writers are not professionally trained. Therefore, social media platforms have to hire professional editors to adjust amateur headlines to attract more readers. We aim to automate the headline editing process to help those independent writers.
Motivation

For most social media, headlines are often the first and only impression to attract readers, and people determine whether to read the article or not based on an instant scan of it. In other words, a good headline will result in many more views. With more views, the writer also receives more commission of advertising revenue from the social media platform. To catch the eyes of readers, the headlines have to be as intriguing as possible. Large media operations usually hire professional editors to edit headlines. These professional editors fix different types of problems that may happen in a headline, including grammatical errors, vague topics, lousy sentence structure, or just simply unattractive headlines. After editing, those well-polished headlines typically receive more attention from social network readers.
In contrast, independent writers cannot afford to hire editors. Even if their articles contain exciting content, if their headlines are not attractive, people will not read them. We want to automate this headline editing process, so that it provides a tool for their headlines to be more attractive.
Professional Headline Editing Dataset (PHED)

The first step before building a model is to collect the dataset.
Unlike other datasets with crowdsourcing, headline editing requires professional skills in writing.
Therefore, we recruited professional editors to help us edit those headlines.
Those editors are experienced social media editors that not only have good writing skills but also understand what type of headlines lead to higher number of views.
Also, since they are professional, the edited headlines must reflect the facts rather than being “clickbaits”.
We only selected articles that the editors think have problems.
Then the editors carefully edited those headlines according to both the original headline and news body.
The goal of editing is that the edited headlines should appear more attractive to the readers.
Finally, we have a dataset with news body along with parallel original and edited headlines for training our model. This professional headline editing dataset (PHED) totally contains about 20,994 articles. It covers six different domains. The detailed statistics is shown below:
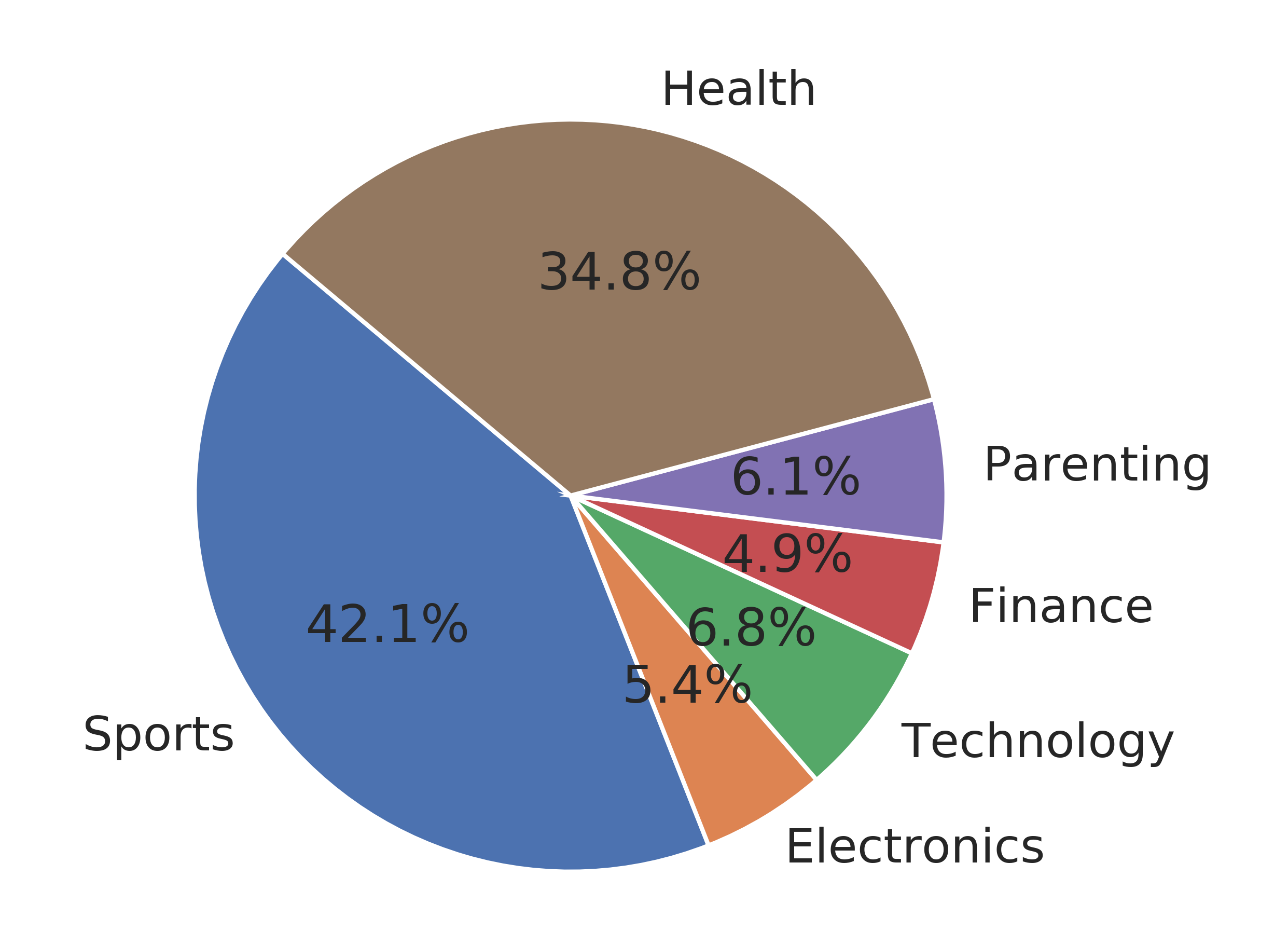
| Categories | Count |
|---|---|
| Sports | 8,837 |
| Health | 7,298 |
| Finance | 1,029 |
| Parenting | 1,283 |
| Technology | 1,419 |
| Electronics | 1,128 |
There is an example:
Original Headline
战术分析:巴西出局的根本原因
Summary
巴西被比利时2-1击败出局,犯错的后腰费尔南迪尼奥成了球迷发泄的出气筒,大家都认为他的表现是灾难级别的。所以巴西出局的根本原因是什么,其实很简单:大举压上,导致后防空虚;将中场的拦截完全放在费尔南迪尼奥一个人身上:所以,当他们的后防有大量空间时,面对阿扎尔。
Edited Headline
巴西队世界杯输在哪?3个镜头曝光真正毒瘤,内马尔也无力回天!
If you are interested in using this dataset, you can find it here.
PAS: Pre-training, Adaptation, and Self Importance-Aware loss
After we have the dataset, the next is to build a model to automate the headline editing process. We build an encoder-decoder with pre-trained Transformer model. To solve low-source problem and repetitions, we leverage pre-training and adaptation; moreover, we propose a Self Importance-Aware loss objective. We use the acronym PAS, which stands for Pre-training, Adaptation, and SIA, to name our final model.
Pre-training
Large scale pre-trainging is proven to be effective in various NLP tasks. It provides the capability of general language understanding. Language models such GPT-2 can generate highly fluent and coherent sentences. Without pre-trainging, our model’s generations are terrible. Therefore, we apply pre-traing before fine-tuning on PHED.
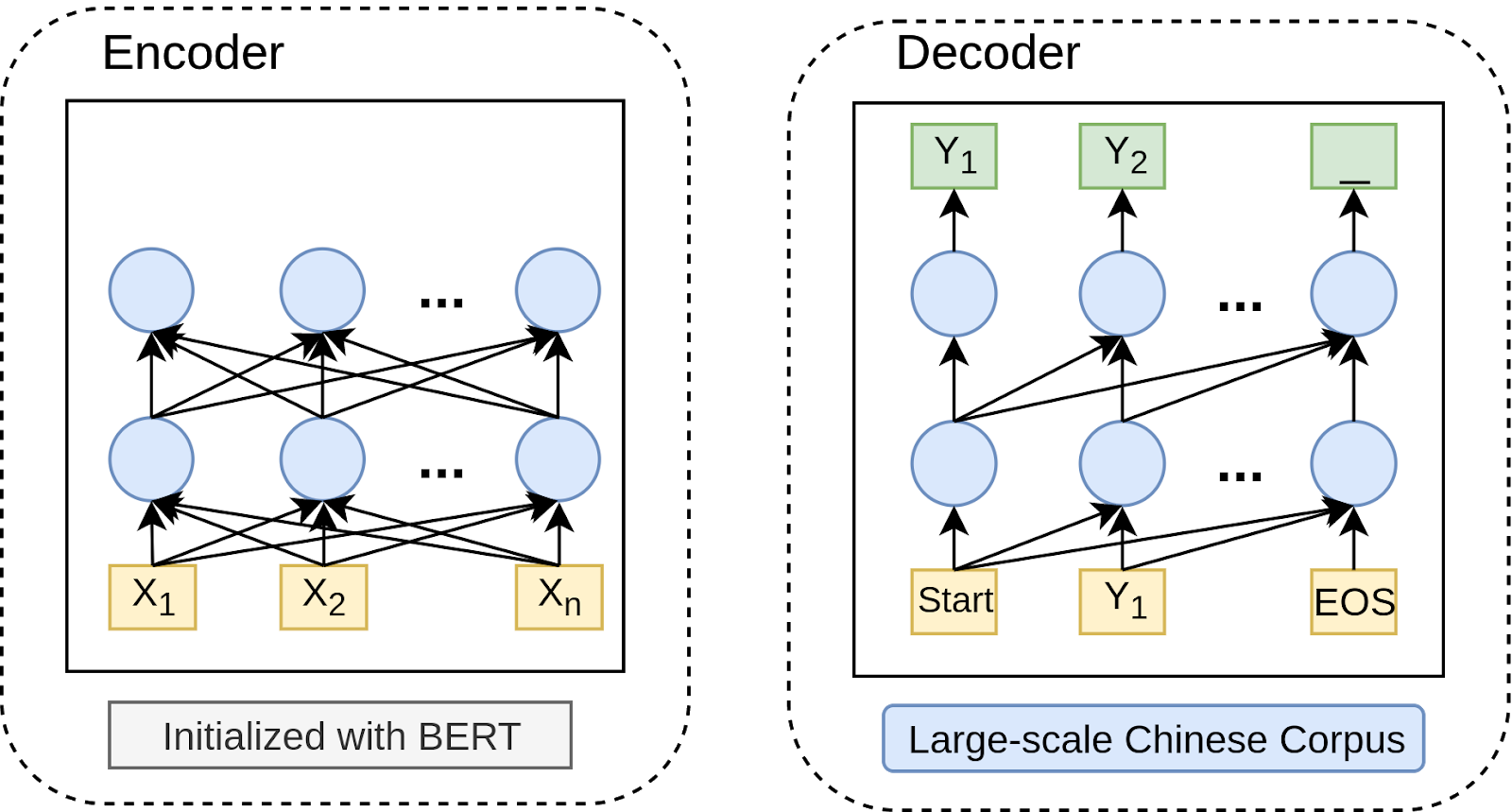
We choose to use the common encoder-decoder structure. Here, the encoder is initialized with Chinese-BERT, which is available in huggingface’s library. However, there was no existing Chinese-GPT for the decoder at that time. We trained our own Chinese-GPT, using public corpus which is about 15.4GB. They include:
- Chinese Wikipedia (wiki2019zh) (1.6GB)
- News (news2016zh) (9.0GB)
- Baike QA (baike2018qa) (1.1GB)
- Community QA (webtext2019zh) (3.7 GB)
You can find this corpus here here.
In addition, we utilized transfer learning with weights from Chinese-BERT. We modified BERT architecture to support state reuse, so that the decoder can fast generate sequences. The mask is also adjusted to be uni-directional instead of being bi-directional. If you are interested in using our pre-trained Chinese language model, it is included in TorchFly.
Adaptation with Headline Generation
Since we only have limited number of samples in our dataset, the results are still not good. To overcome this low-resource challenge, we have to find a close-related task to adapt the model. During PHED dataset collection, we have a large number (over one million) of unused news articles with their headlines. Thus, we use headline generation as the adaptation task to further pre-train the model.
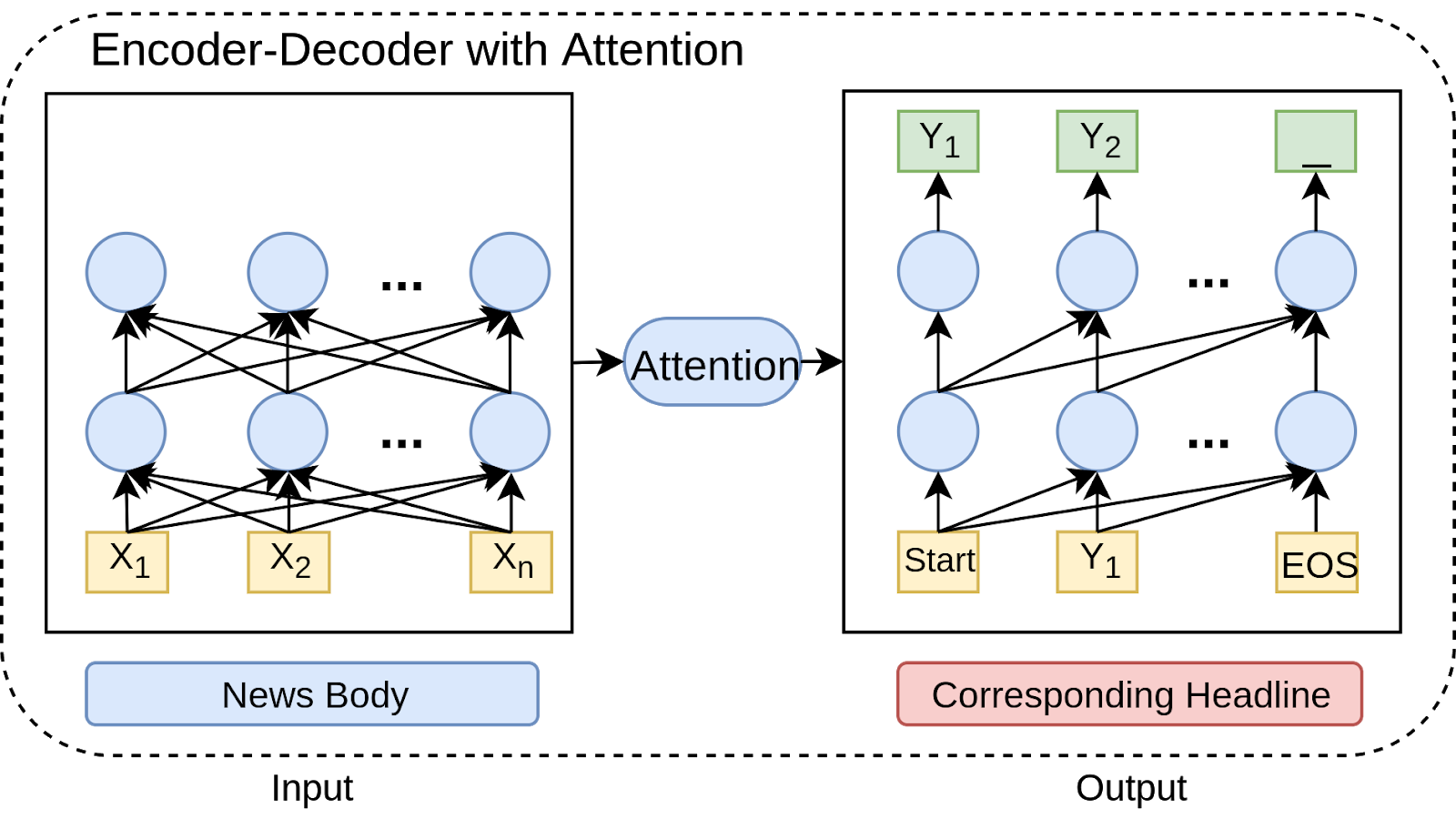
In this task, the news body is used as inputs, and output for the decoder is the corresponding headlines. We used the encoder-decoder from previous stage for this task.
Self Importance-Aware (SIA) Loss
With pre-training and adaptation, the results finally look acceptable. However, another challenge is that we have observed a lot of repetitve patterns. Those patterns can happen at token-level or sentence-level. They greatly reduce the diversity of generations. For example, it is very common to text phrases such as “医生提醒”, “终于找到xx惨败的原因了”. Although users might not be sensitive to those patterns at first, eventually users might feel tired. Then it is important to find a solution for this problem.
The repetion problem is considered to be caused by MLE loss mentioned in the unlikelihod training paper. Inspired by Focal Loss, we further suspect it is due to the imbalance of importance for each token and sequence. For example, some certain words in a language are less importance, like “is”, “are”, “a”, etc. Some sequences are also easier to learn than others, like “hello, how are you?”. However, in MLE loss, those words and sequences share the weight. To remedy this, we propose self importance-aware (SIA) loss.
The main idea is to have two weights to control the importance of each token and sequence. \(w_t\) is for the token-level and \(w_s\) is for the sequence level. Then we define them as follow:
\[\begin{eqnarray} w_t &=& (1 - p(y_t | y_{< t}))^\alpha \\ w_s &=& (1 - \prod_{t=1}^T \, p(y_t | y_{< t}))^\beta \end{eqnarray}\]where \(y_t\) means the ground truth token at time step \(t\). \(\alpha\) and \(\beta\) controls the degree of importance.
Next, we combine \(w_t\) and \(w_s\) together with MLE loss which is the SIA loss:
\[\begin{equation} \mathcal{L_{\textrm{SIA}}} = - w_s \sum_{t=1}^T w_t \log p(y_t | y_{<t}) \end{equation}\]This loss function can be used similarly as MLE during training, without any additional changes. It is also computationally effcient compared to some other methods such as data re-weighting, or boosting because we do not need to maintain a list of previous sentences for calculating repetition. One limitation is that this can only be used for pre-trained models, otherwise the estimation of the two weights would be inaccurate in the beginning of the training.
How to adjust \(\alpha\) and \(\beta\)
Another problem is what should be the value for the two new hyper-parameters \(\alpha\) and \(\beta\). We have conducted grid search to find relatively best values.
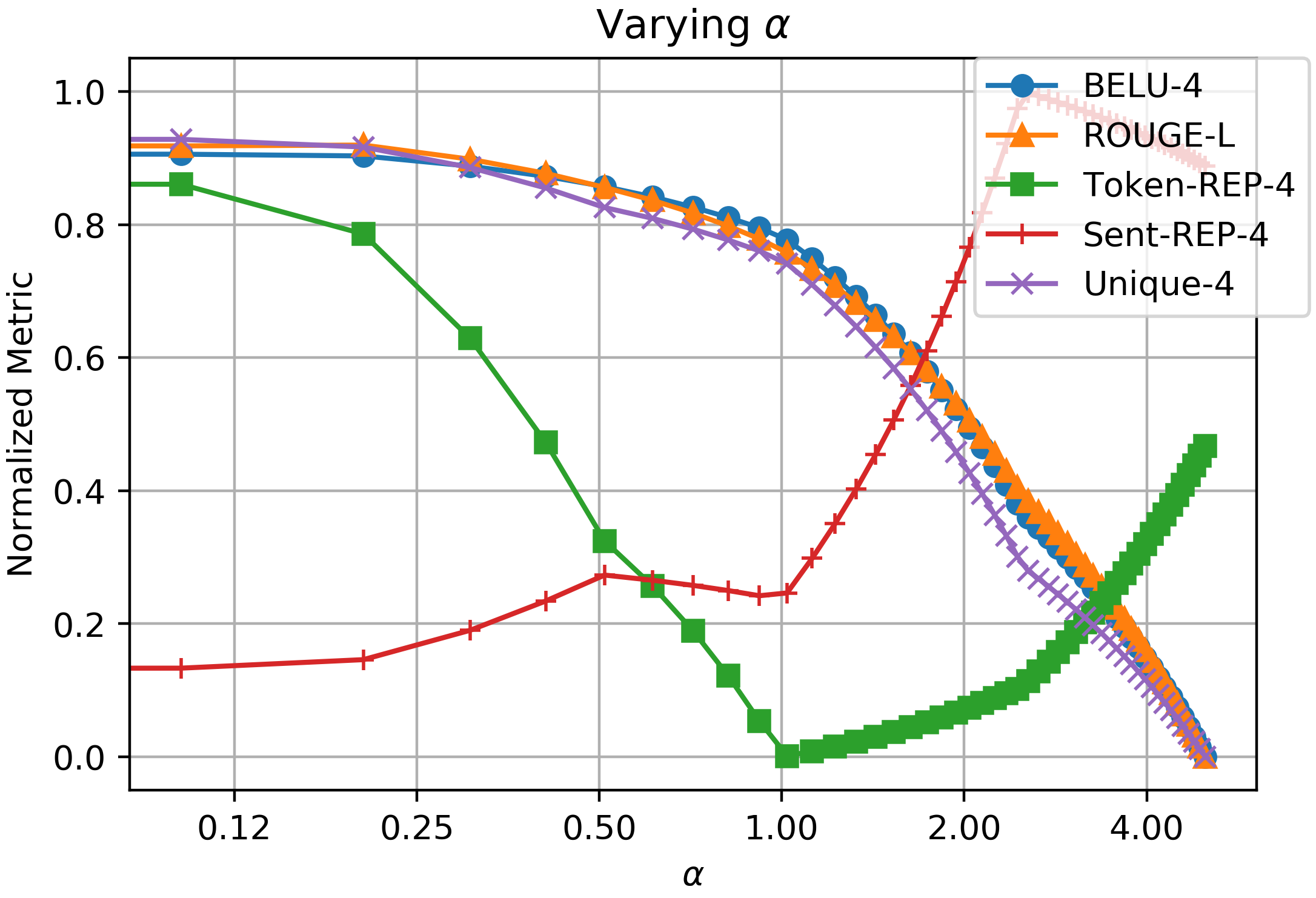
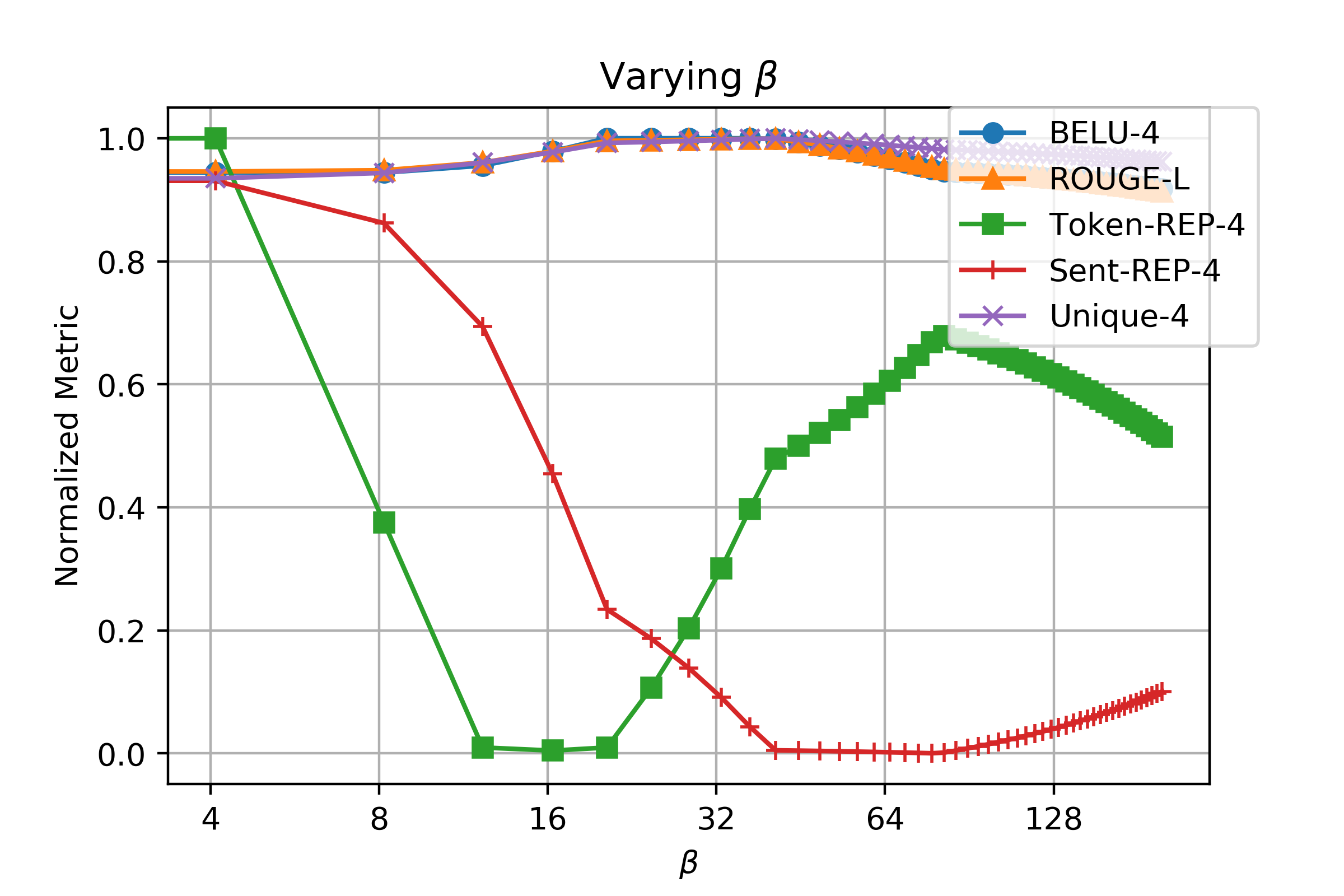
From the two graphs, we can observe that there is a trade-off for \(\alpha\) and \(\beta\). If their values are too large, it would result in worse performance. Especially \(\alpha\) is very sensitive, but changing \(\beta\) is much more tolerant. In the end, we choose \(\alpha = 0.2\) and \(\beta = 40.0\) as the final values. As SIA is under exploration, we welcome people to test SIA on more tasks.
Automatic Evaluation
Performance results of all models. Across models, we compare fine-tuning at different stages with different loss functions. Other than perplexity, bleu-4, and rouge-l, we use three other automatic evaluation metrics to measure diversity.
- Token-REP-4 is the token-level repetition inside a sequence. In specific, we count the previously occured 4-grams and report the normalized score.
- Sent-REP-4 is the sentence-level repetition inside the corpus. We count how many 4-grams in a sequence also occured inside the corpus. We report the normalized score.
- Unique 4-grams is the number of unique 4-grams counted in the test set.
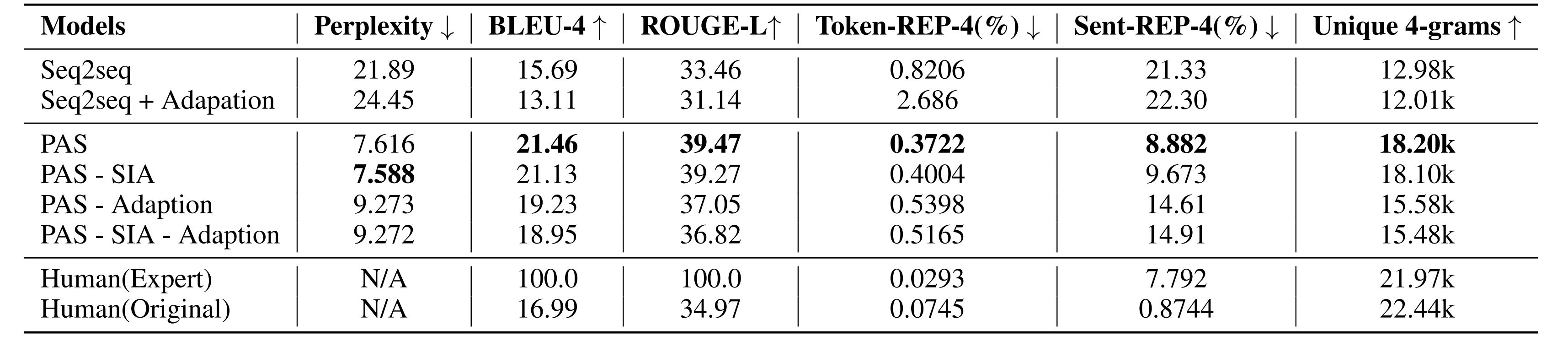
From the table, our PAS achieves overall the best results with slight performance loss in perplexity. SIA helps to improve not only the n-gram
Human Evaluation

We have also conducted human evaluation to further evaluate our model. PAS is shown better than PAS without Adaptation and SIA. Also, PAS generated headlines mimic the style of ground truth edited headlines, and they are more preferred by human evaluators.
Conclusion
We propose a new headline editing task (to generate more attractive headlines), and come up with the dataset PHED. We show that pre-training and adaptation help to improve the quality of generations. The SIA loss is still experimental, but we believe that it can have potentials being used in other tasks. For future work, since it is still expensive to collect paired original-edited headlines, we want to explore unsupervised methods without using any paired data.
You can cite with:
@inproceedings{importance-aaai2020,
author = {Qingyang Wu and
Lei Li and
Hao Zhou and
Ying Zeng and
Zhou Yu},
title = {Importance-Aware Learning for Neural Headline Editing},
booktitle = {Proceedings of the Thirty-Fourth {AAAI} Conference on Artificial Intelligence,
February 7-12, 2020, New York, New York, {USA}},
year = {2020}
}